以前の記事で,plotlyを使ったヒストグラムの作成法について詳しくご紹介しました。
ヒストグラムを作図するとき,ヒストグラムの近似曲線なども併せて作図したいと思ったことはないでしょうか?
そのようなとき,plotlyのモジュールの一つ Figure Factoryを使うと簡単に作図ができます。
Figure Factoryを使い,「ヒストグラム+近似曲線」の作図を行う
目標とするグラフは↓です。
*このグラフのコードは,最後のまとめにあります。一括でコピペしたい場合は,そちらを参考にしてください。

Figure Factoryを使う
Figure Factoryは,plotlyのモジュールの一つです。
モジュールはその他にPlolty Express と Graph Objectsがあります。
まず,Plolty Express と Graph Objects違いを簡単に確認します。

Plolty Expressは少ないコードでグラフが作成できる一方で、作成できない3次元グラフやサブプロットがあります。
それらのグラフは,Graph Objectで作成可能です。
また,Plolty Expressの内部で結局Graph Objectが呼び出されており,本ブログではGraph Objectsを使用しています。公式説明はこちらです。
“Figure Factory”ですが,”Plolty Express”が作られるより前に,”Graph Objects”で作成するのが面倒なグラフを作成するためのモジュールでした。
そのため,”Plolty Express”で機能が実装されると非推奨となる機能もありますが,今回の「ヒストグラム+近似曲線」はまだ非推奨ではないので,“Figure Factory”を使い紹介したいと思います。
Figure Factoryのplotly公式説明はこちらにありますので,ご確認ください。
データ,ライブラリの読み込み
今回,作図するデータとしてscikit-learnのワインのデータセット(公式サイト)を使います。
ライブラリにはsklearn, pandas, そしてplotlyのFigure Factoryを使います。
#ライブラリのインポート
from sklearn import datasets
import pandas as pd
from plotly.figure_factory import create_distplot
#ワインデータの読み込み
data = datasets.load_wine()
X=data['data']
Y=data['target']
wine_X = pd.DataFrame(X, columns=data['feature_names'])
df_wine = wine_X.copy()
df_wine['target']=Y
df_winedf_wineの中身は↓のようになっております。
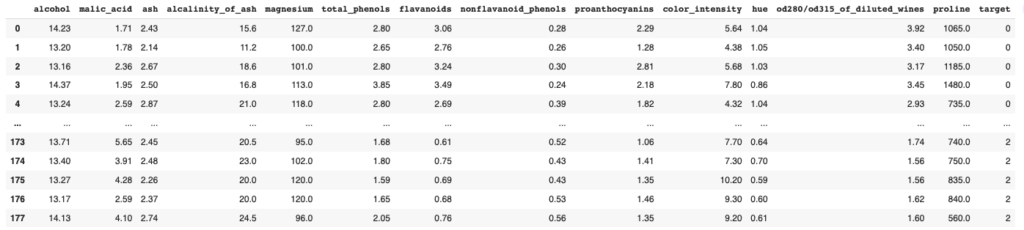
この中で”alcohol”のデータを使います。
Figure Factoryのdistplotによる作図
細かな設定は後でまとめるので,まずはFigure Factoryのdistplotによる作図法を確認します。
公式HPはこちらをご確認ください。
この章では,↓の”ヒストグラム+近似曲線+rug”の作図を行います。
コードは↓です。
#ヒストグラムの作図
fig = create_distplot(hist_data=[df_wine['alcohol'].values], group_labels=['alcohol'])
# 軸ラベル
fig.update_xaxes(title='alcohol')
fig.update_yaxes(title='probability density')
fig.show()4,5行目で軸のタイトルを設定していますが,基本的には2行目のcreat_distplot(…)で上記のグラフが作図できます。
ヒストグラムのデータなどはリストで渡す必要があることはご注意ください。
このため,[df_wine[‘alcohol’].values] としています。
設定の詳細は下記をご確認ください。
fig = creat_distplot(hist_data= <VALUE>,
group_labels= <VALUE>,
)| hist_data= ○○○ | ヒストグラムのデータ *リストで渡す |
| group_labels= ○○○ | データの判例名 *リストで渡す |
設定項目一覧
ここでは,設定できる項目を一覧でまとめます。
以下のグラフとコードを基に,それぞれの設定を変えたときに,グラフがどのように変化するか見ていきます。
fig = create_distplot(hist_data=[df_wine['alcohol'].values],
group_labels=['alcohol'],
colors=['blue'],
bin_size=0.5,
curve_type='kde',
histnorm='probability density',
show_hist=True,
show_curve=True,
show_rug=True
)
# 軸ラベル
fig.update_xaxes(title='alcohol')
fig.update_yaxes(title='probability density')
fig.show()Figure Factoryのdistplotで設定できる項目は以下です。
fig = creat_distplot(hist_data= <VALUE>,
group_labels= <VALUE>,
colors= <VALUE>,
bin_size= <VALUE>,
curve_type= <VALUE>,
histnorm= <VALUE>,
show_hist= <VALUE>,
show_curve= <VALUE>,
show_rug= <VALUE>,
)| hist_data= ○○○ | ヒストグラムのデータ *リストで渡す |
| group_labels= ○○○ | データの判例名 *リストで渡す |
| colors= ○○○ | ヒストグラムの色 *リストで渡す |
| bin_size= ○○○ | ビンのサイズ |
| curve_type= ○○○ | 近似曲線の設定,以下から選択 “kde” :カーネル密度推定(default) “normal” :正規分布 |
| histnorm= ○○○ | 正規化表現の設定,以下から選択 “probability density”: 確率密度による正規化表現 “probability” :y軸全体の合計を1にする正規化表現 |
| show_hist= ○○○ | ヒストグラムの表示設定、以下から選択 “True” : 表示する(default) “False” : 表示しない |
| show_curve= ○○○ | 近似曲線の表示設定、以下から選択 “True” : 表示する(default) “False” : 表示しない |
| show_rug= ○○○ | rugの表示設定、以下から選択 “True” : 表示する(default) “False” : 表示しない |
それぞれの項目について,見ていきます。
*以下のページからは読み込み速度軽減のため,グラフが一部pngです。
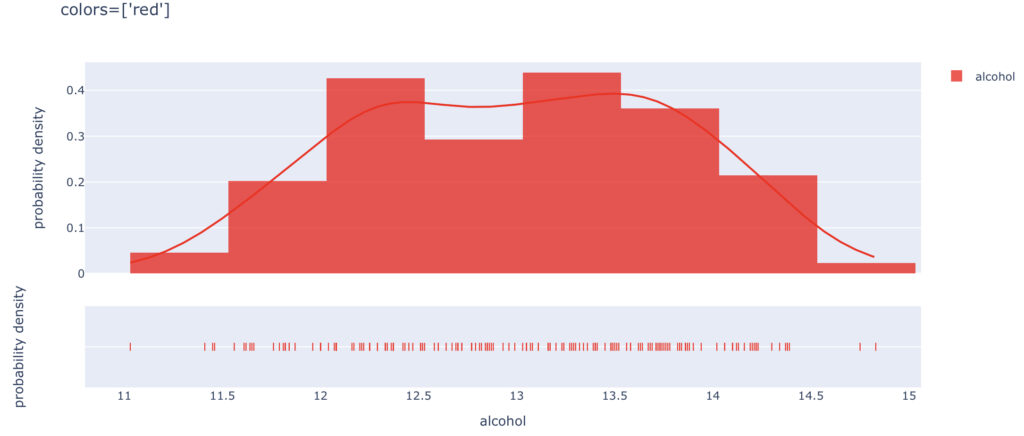
colors
まずは”color”を変更してみます。
以下はcolors=[‘red’]としています。
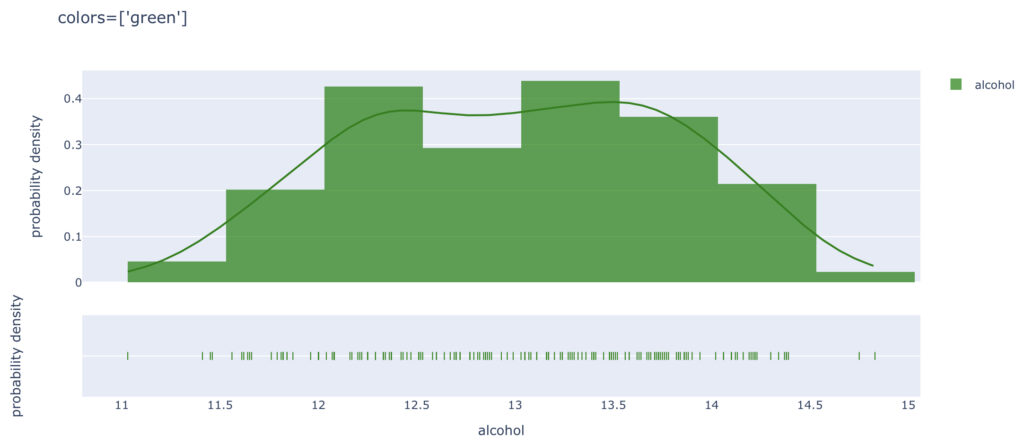
こちらは,colors=[‘green’]です。
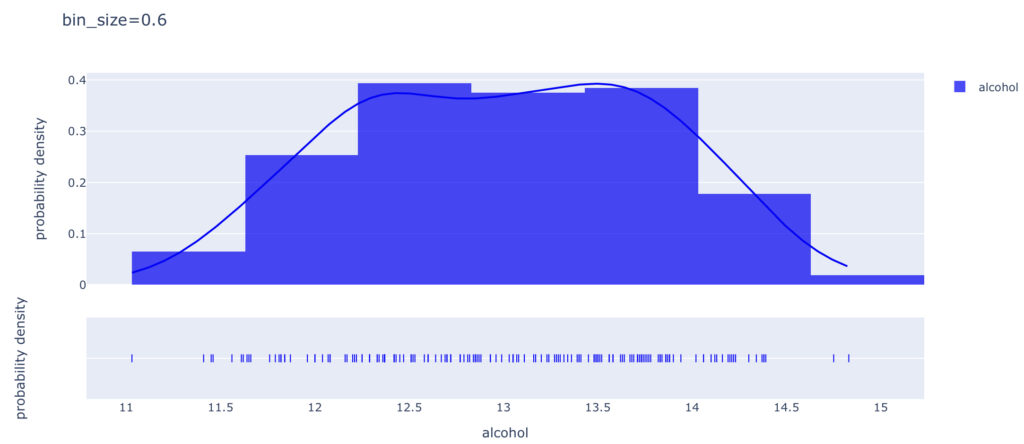
bin_size
続いて,”bin_size”を変更したときのグラフをみてみます。
以下のグラフは,”bin_size=0.1”, ”bin_size=0.6”です。
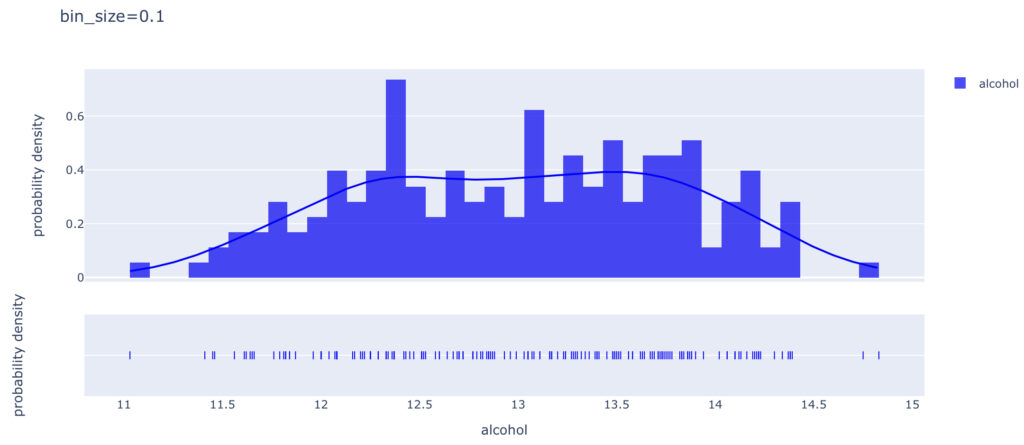
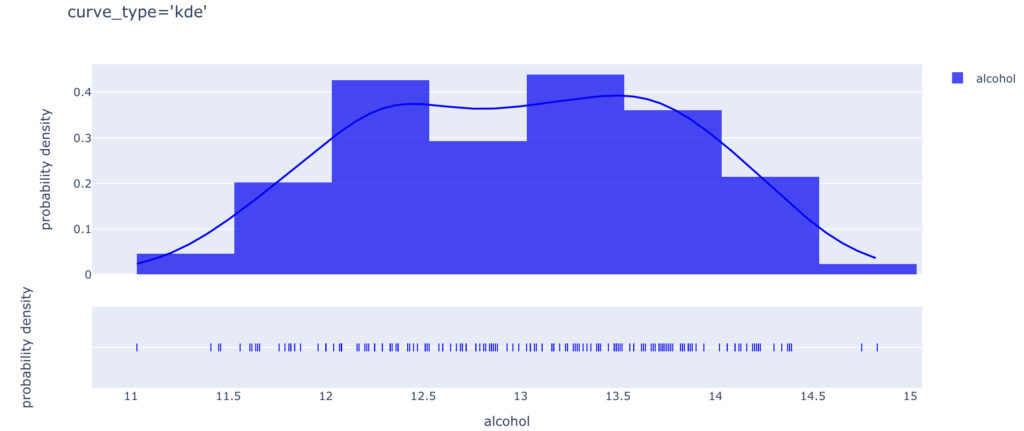
curve_type
“curve_type”で選択できる”kde”と”normal”の違いを確認します。
- “kde” :カーネル密度推定(default)
- “normal” :正規分布
まずはこちら↓がcurve_type=“kde”のグラフです。
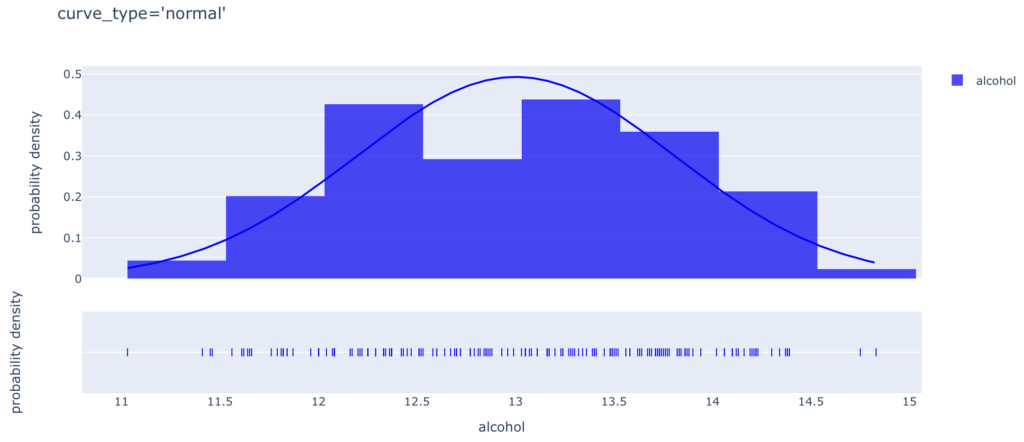
続いて,こちら↓がcurve_type=“normal”のグラフです。
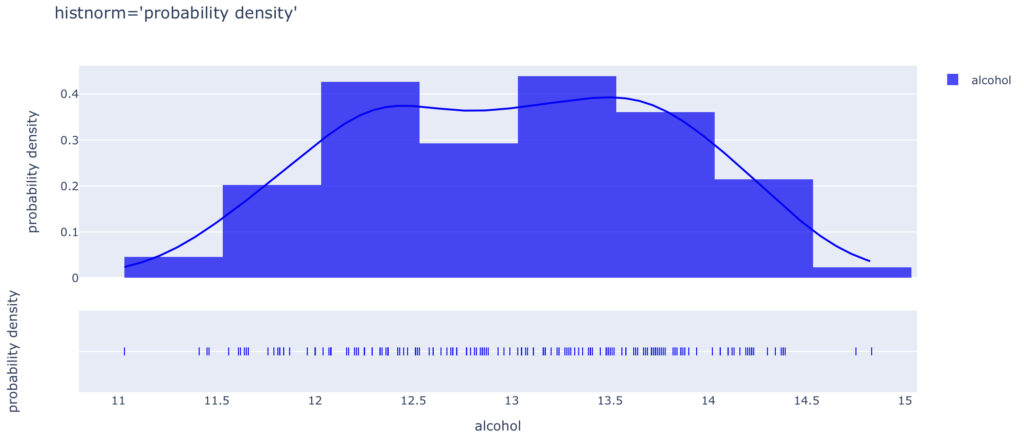
histnorm
さらにhistnorm=“probability density”とhistnorm=“probability”によるグラフの違いを確認します。
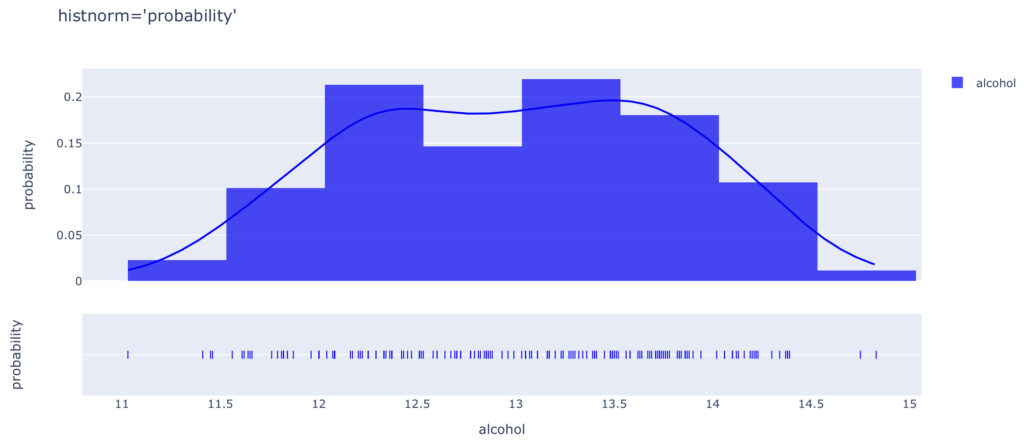
show_hist
show_hist=False とすることで,以下のようにヒストグラムを非表示にできます。
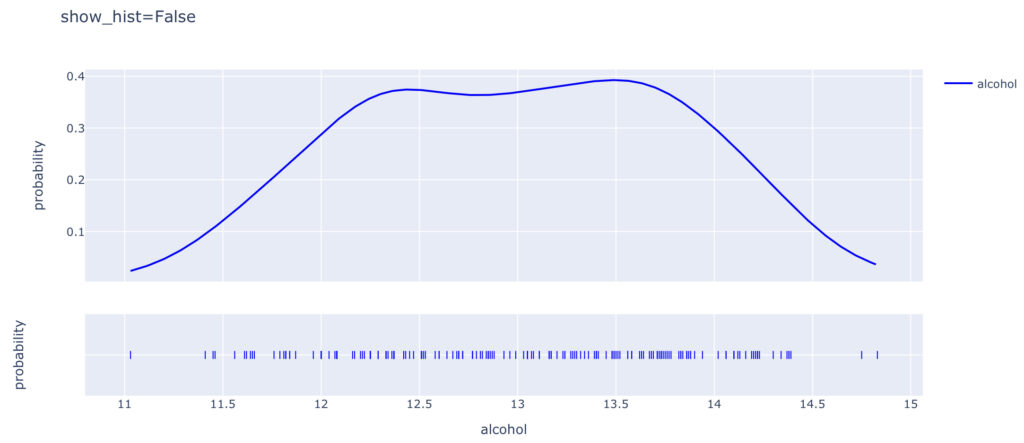
show_curve
show_curve=False では,以下のように近似曲線を非表示にします。
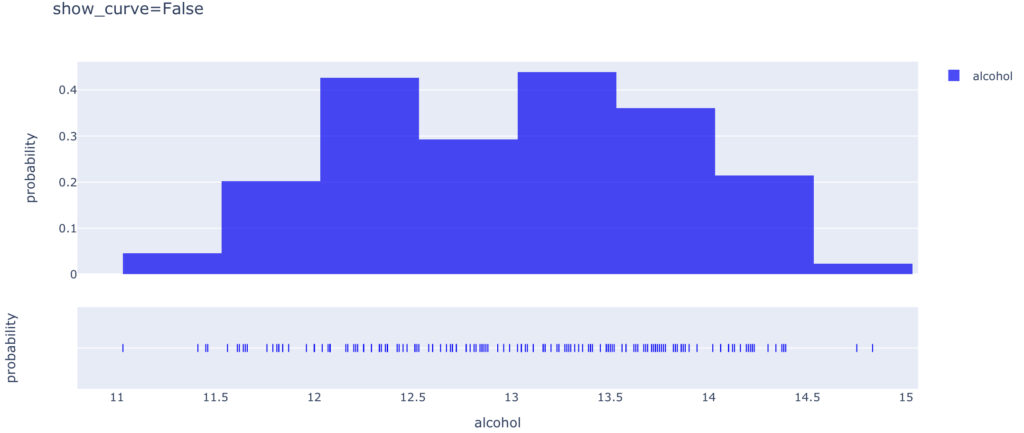
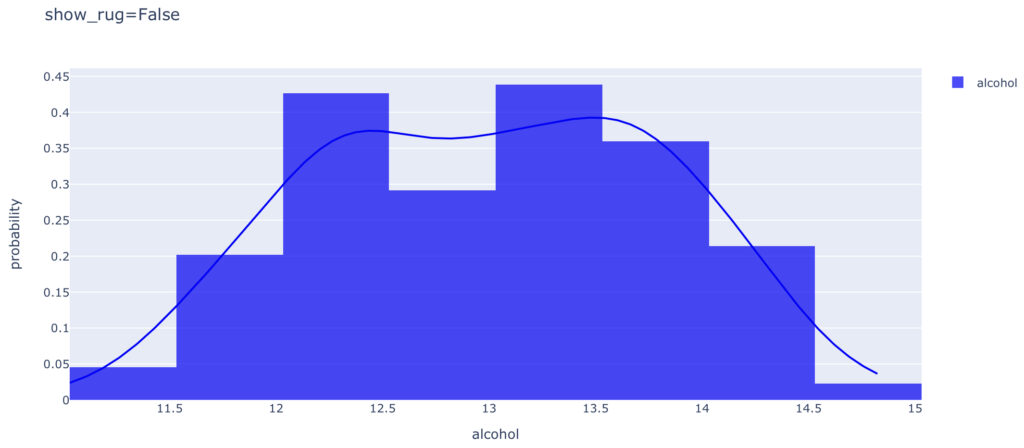
show_rug
最後にshow_rug=False とすると,rugを非表示にできます。
複数データのdistplotによる作図
複数のデータで,Figure Factoryのdistplotを使用する方法を確認します。
これまでワインのデータセットの中の”alcohol”のデータを使用してきました。
ただし,このデータセットは3種類のワインから構成されており,ワインの種別については区別していませんでした。
ここでは,ワインの種別ごとに以下のようにグラフを作成しました。
グラフのコードは以下の通りです。
#データの分割
wine_target0=df_wine[df_wine['target']==0]['alcohol'].values
wine_target1=df_wine[df_wine['target']==1]['alcohol'].values
wine_target2=df_wine[df_wine['target']==2]['alcohol'].values
#ヒストグラムの作成
fig = create_distplot(hist_data=[wine_target0,wine_target1,wine_target2],
group_labels=['wine_target0', 'wine_target1', 'wine_target2'],
bin_size=0.5,
curve_type='normal',
histnorm='probability density',
show_hist=True,
show_curve=True,
show_rug=True
)
# 軸ラベル
fig.update_xaxes(title='alcohol')
fig.update_yaxes(title='probability density')
fig.show()まず2-4行目でワインの種別ごとに,データの分割を行なっています。
hist_dataと group_labelsのそれぞれのリストに複数のデータを入れることで,先ほどのグラフを作成できます。
colorsについては,自動で色分けされるのでここでは指定しませんでした。
この記事冒頭のグラフは色を指定していますので,指定したい場合はそちらをご確認ください。
Plolty Expressによるヒストグラムの作図
本題とは少しそれますが,Plolty Expressを使ってもrugを追加できます。
Plolty Expressでは”rug”だけでなく,”box”, “violin”, “histogram”に変更することもできます。
以下は,Plolty Expressによる”rug”表記のグラフです。
コードは↓です。
import plotly.express as px
fig = px.histogram(data_frame= df_wine,
x='alcohol',
histnorm='probability density',
histfunc='count',
marginal='rug' #'rug', 'box', 'violin', or 'histogram')
)
fig.show()
Plolty Expressを使うために,1行目でimportしています。
3-8行目でヒストグラムの各種項目の設定をしています。
以下で,今回の設定した項目をまとめています。
設定できる項目の一覧は,公式HPをご確認ください。
fig = creat_distplot(data_frame= <VALUE>,
x= <VALUE>,
histnorm= <VALUE>,
histfunc= <VALUE>,
marginal= <VALUE>,
)| data_frame= ○○○ | ヒストグラムのデータ |
| x= ○○○ | データの判例名 |
| histnorm= ○○○ | 以下の5つから選択 “” : 度数表現(正規化しない) ”percent” : y軸全体の合計を100%にする正規化表現 “probability” : y軸全体の合計を1にする正規化表現 “density” : y軸を(度数)/(階級幅)の密度にする正規化表現 ”probability density” : “density”の面積全体を1にする正規化表現 |
| histfunc= ○○○ | 以下の5つから選択,ただしy=○○○の値に適用 “count”: 度数,データ個数による表現 ”sum” : 合計値による表現 “avg” : 平均値による表現 “min” : 最小値による表現 ”max” : 最大値による表現 |
| marginal= ○○○ | “rug”, “box”, “violin”, “histgram” から選択 |
marginalを“box”, “violin”, “histgram”と変えた時のグラフを以下で見ていきます。
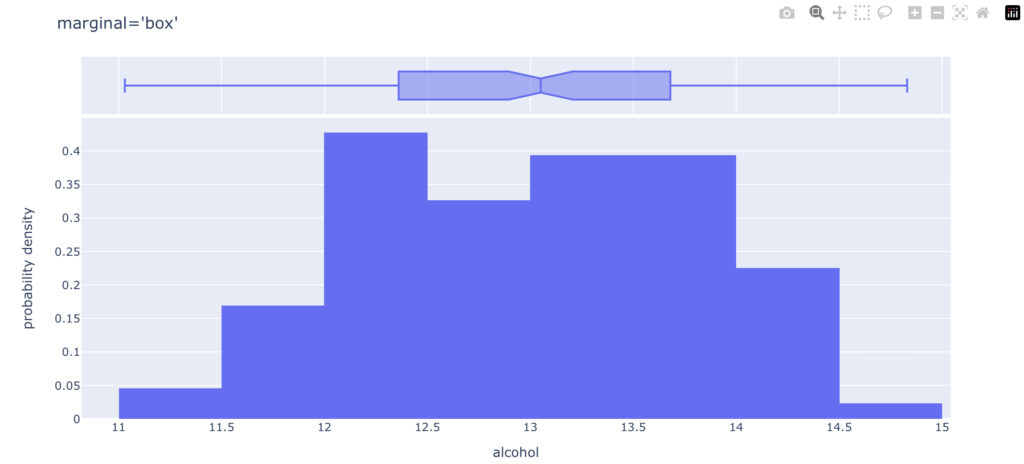
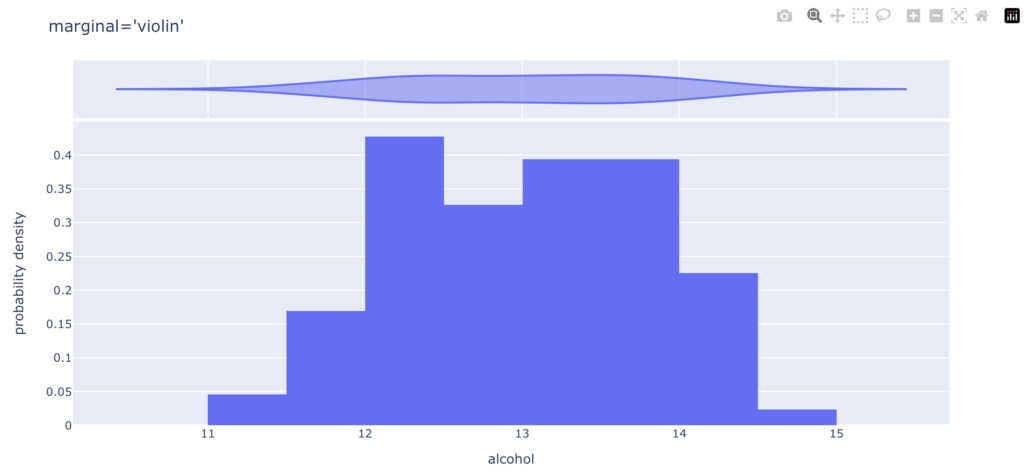
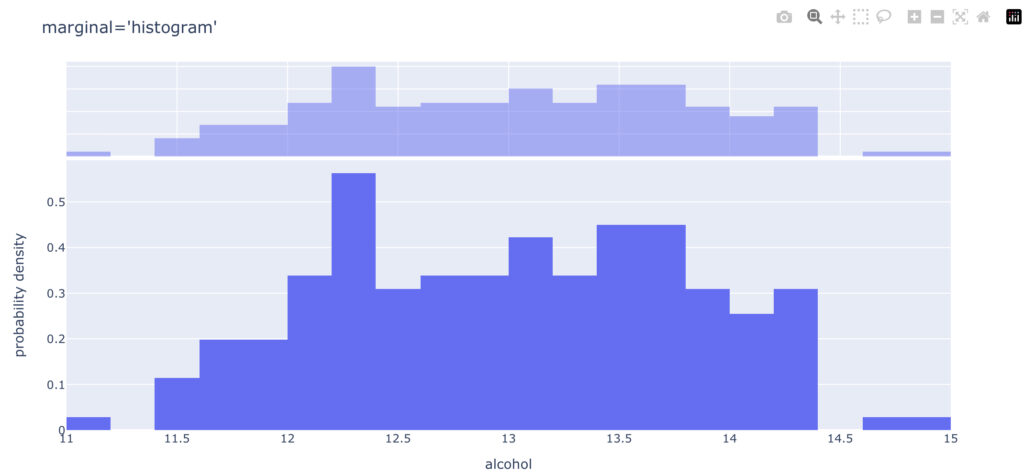
まとめ
Figure Factoryのdistplotによる作図法をみてきました。
以下で,本記事で紹介した設定項目をまとめます。
fig = creat_distplot(hist_data= <VALUE>,
group_labels= <VALUE>,
colors= <VALUE>,
bin_size= <VALUE>,
curve_type= <VALUE>,
histnorm= <VALUE>,
show_hist= <VALUE>,
show_curve= <VALUE>,
show_rug= <VALUE>,
)| hist_data= ○○○ | ヒストグラムのデータ *リストで渡す |
| group_labels= ○○○ | データの判例名 *リストで渡す |
| colors= ○○○ | ヒストグラムの色 *リストで渡す |
| bin_size= ○○○ | ビンのサイズ |
| curve_type= ○○○ | 近似曲線の設定,以下から選択 “kde” :カーネル密度推定(default) “normal” :正規分布 |
| histnorm= ○○○ | 正規化表現の設定,以下から選択 “probability density”: 確率密度による正規化表現 “probability” :y軸全体の合計を1にする正規化表現 |
| show_hist= ○○○ | ヒストグラムの表示設定、以下から選択 “True” : 表示する(default) “False” : 表示しない |
| show_curve= ○○○ | 近似曲線の表示設定、以下から選択 “True” : 表示する(default) “False” : 表示しない |
| show_rug= ○○○ | rugの表示設定、以下から選択 “True” : 表示する(default) “False” : 表示しない |
冒頭のグラフのコードはこちら
#ライブラリのインポート
from sklearn import datasets
import pandas as pd
from plotly.figure_factory import create_distplot
#ワインデータの読み込み
data = datasets.load_wine()
X=data['data']
Y=data['target']
wine_X = pd.DataFrame(X, columns=data['feature_names'])
df_wine = wine_X.copy()
df_wine['target']=Y
df_wine
#データの分割
wine_target0=df_wine[df_wine['target']==0]['alcohol'].values
wine_target1=df_wine[df_wine['target']==1]['alcohol'].values
wine_target2=df_wine[df_wine['target']==2]['alcohol'].values
#ヒストグラムの作図
fig = create_distplot(hist_data=[wine_target0,wine_target1,wine_target2],
group_labels=['wine_target0', 'wine_target1', 'wine_target2'],
colors=['orange', 'green', 'blue'],
bin_size=0.5,
curve_type='normal',
histnorm='probability density',
show_hist=True,
show_curve=True,
show_rug=True
)
# 軸ラベル
fig.update_xaxes(title='alcohol')
fig.update_yaxes(title='probability density')
fig.show()読了お疲れ様でした!
以上,【plotly】これでわかる!ヒストグラムの作図方法 でした!

コメント